Constructing Loss functions with the MDMM method.
Linear combinations of losses require tuning a coefficient using trial and error because its effect on the learner is unknown until training is evaluated after some time.
If you could set the second loss to the value you wanted, you wouldn’t need to sweep coefficient values.
The Modified Differential Method of Multipliers (MDMM) lets you minimise a loss function subject to equality, inequality or bound constraints on arbitrarily many secondary functions to your problem’s parameters, this by replacing loss_A + (λ * loss_B) with minimize loss_A subject to loss_B.
Here are two sets of examples to illustrate the instability of linear combinations of losses and why algorithms are so sensitive to hyperparameters.
Concave pareto fronts (without mdmm, then with mdmm)
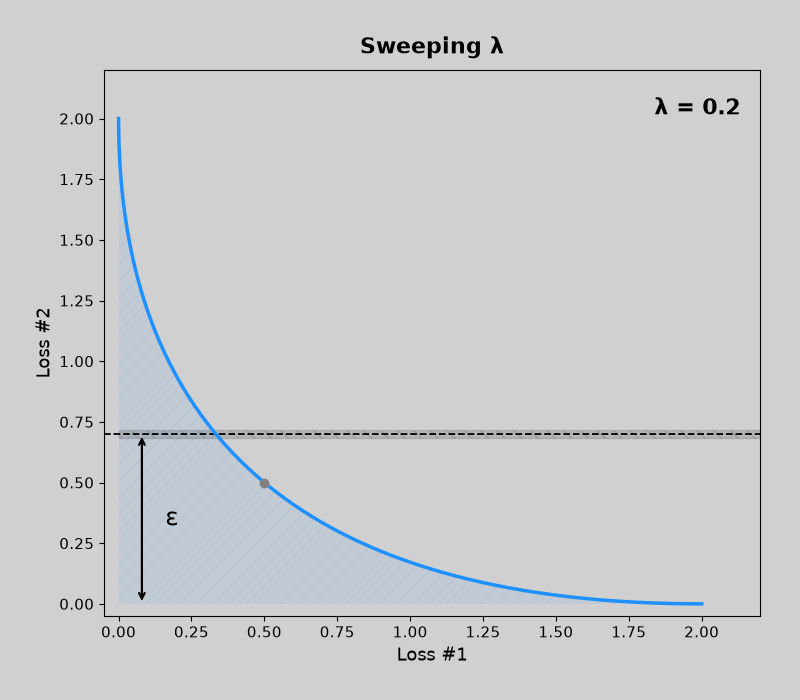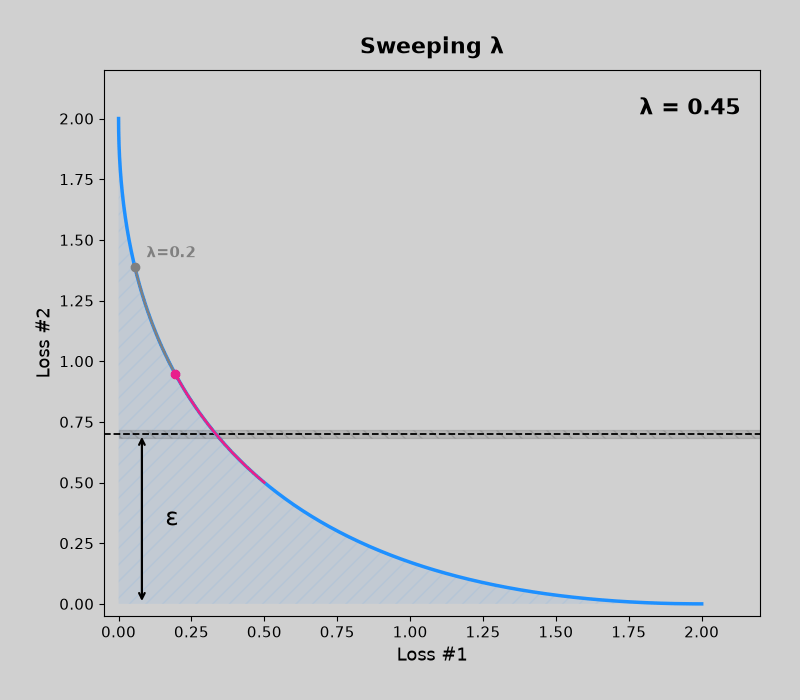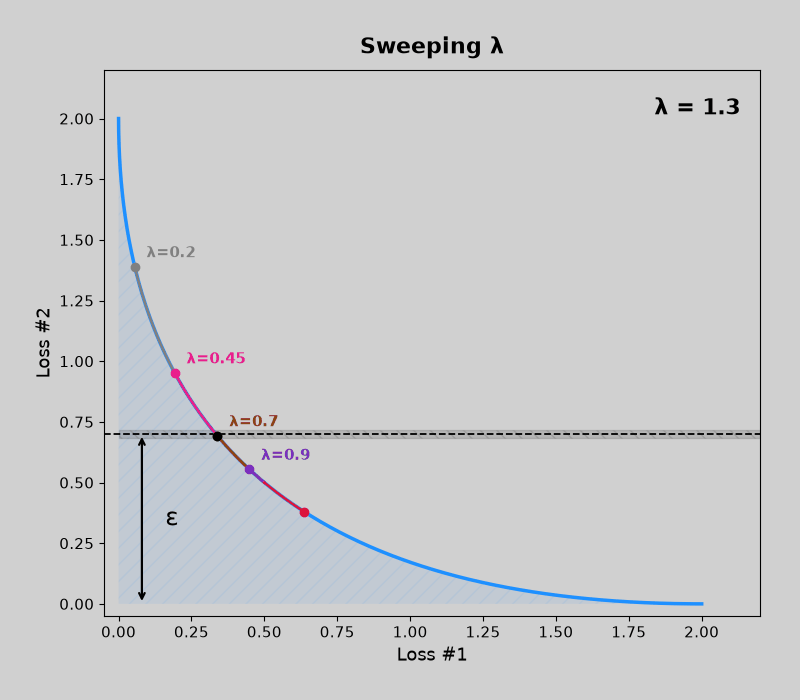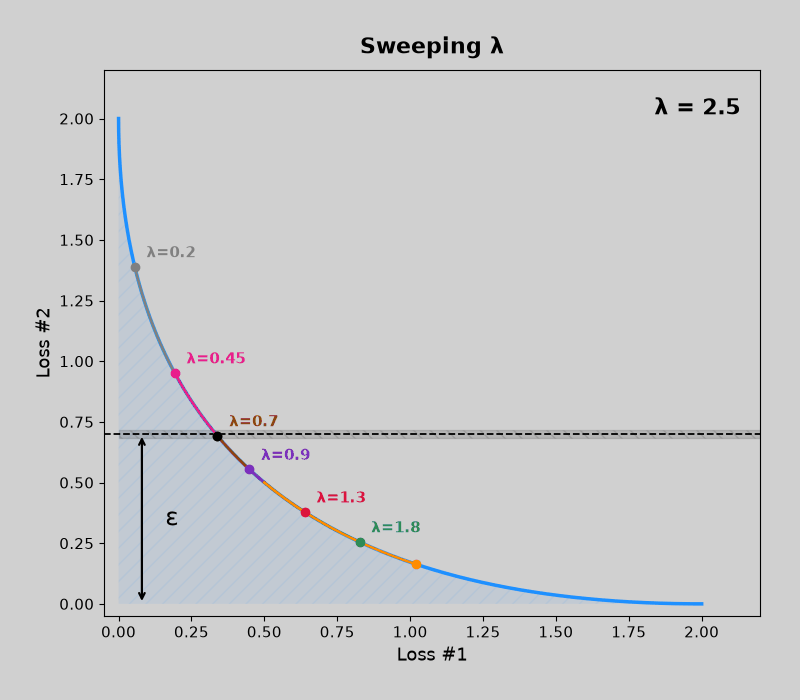
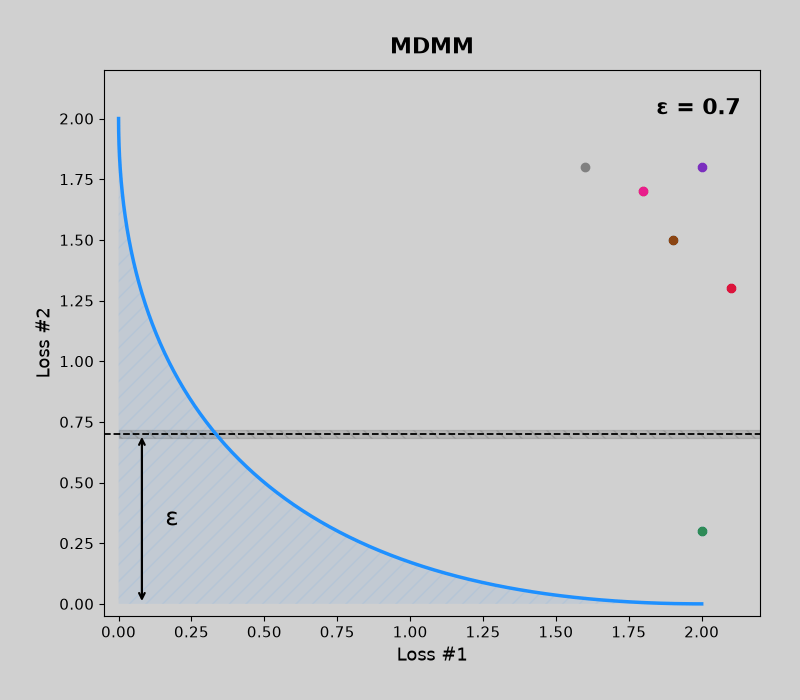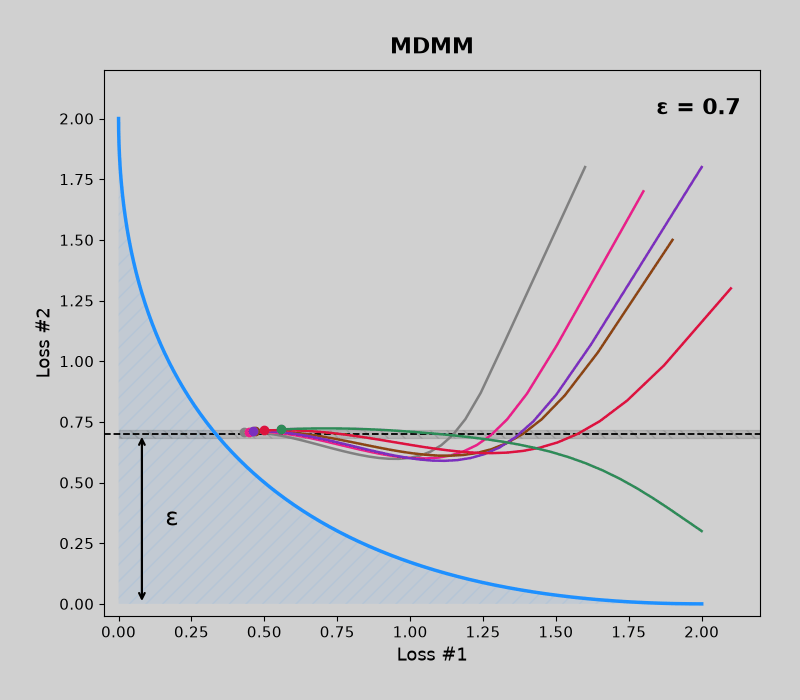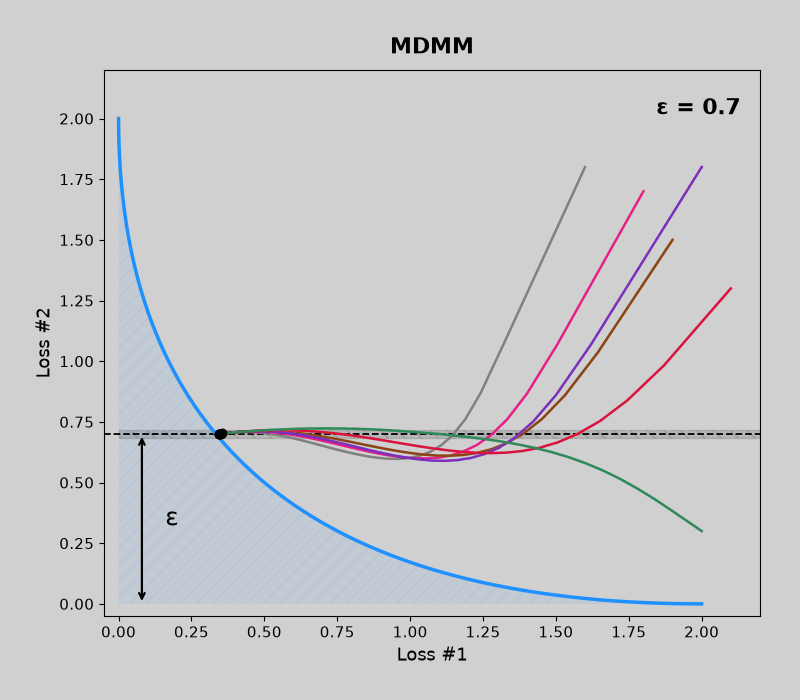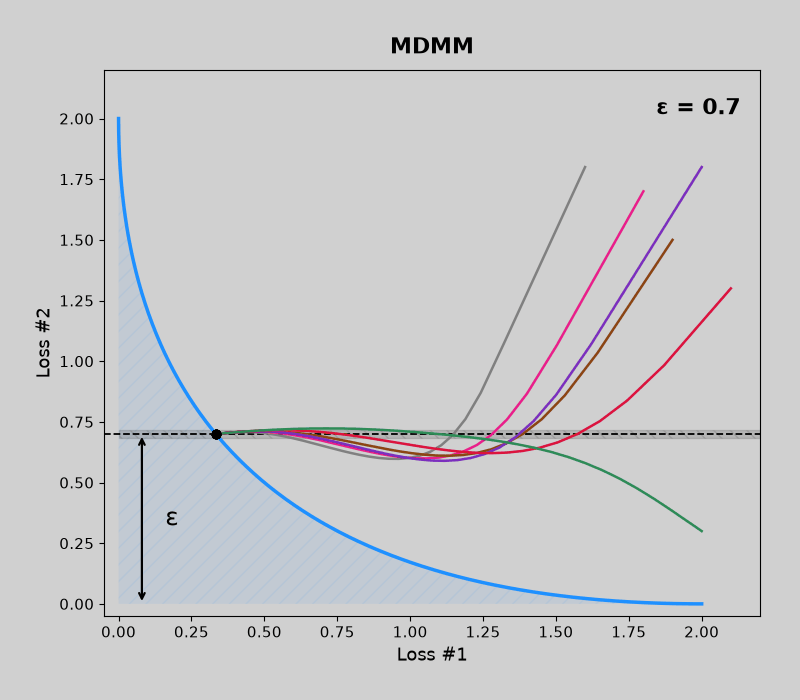
Convex pareto fronts (without mdmm, then with mdmm)
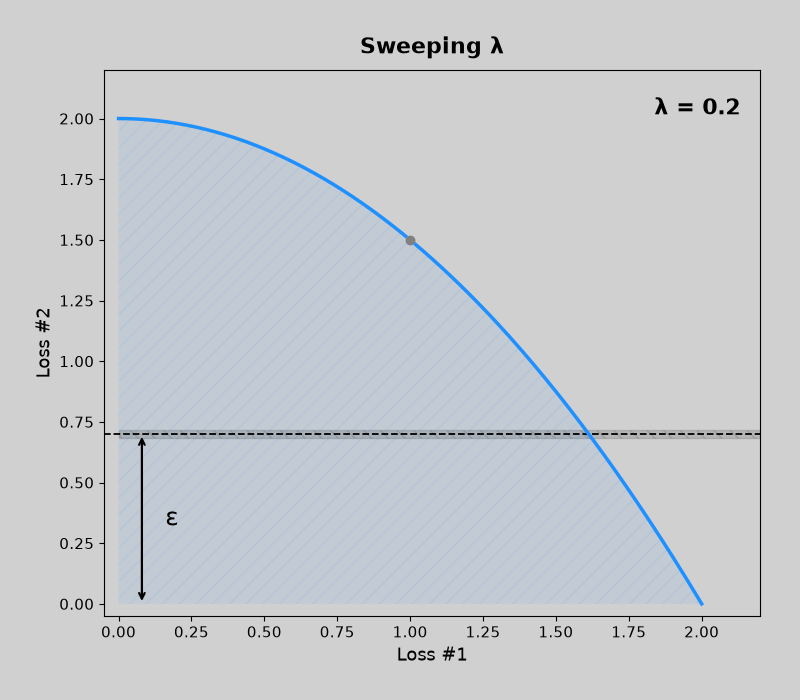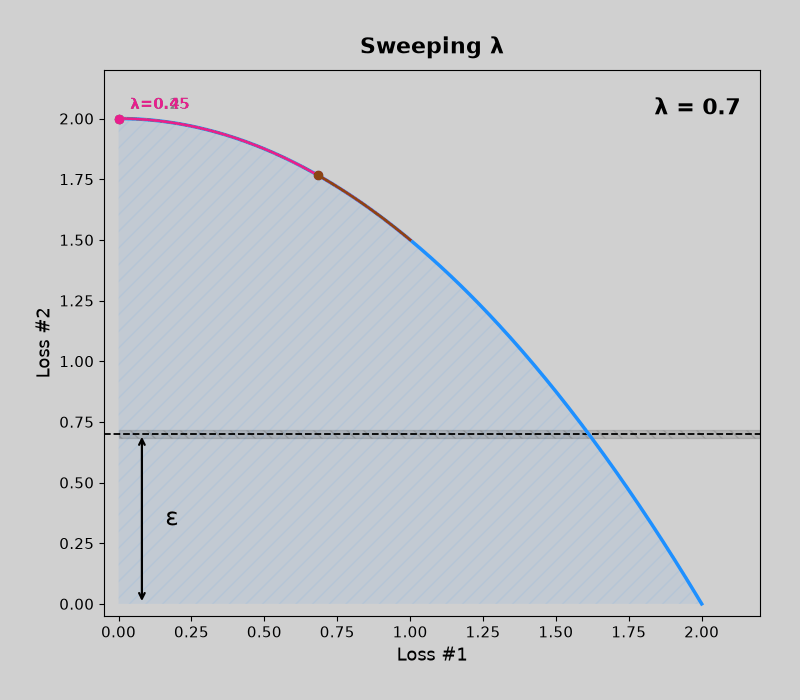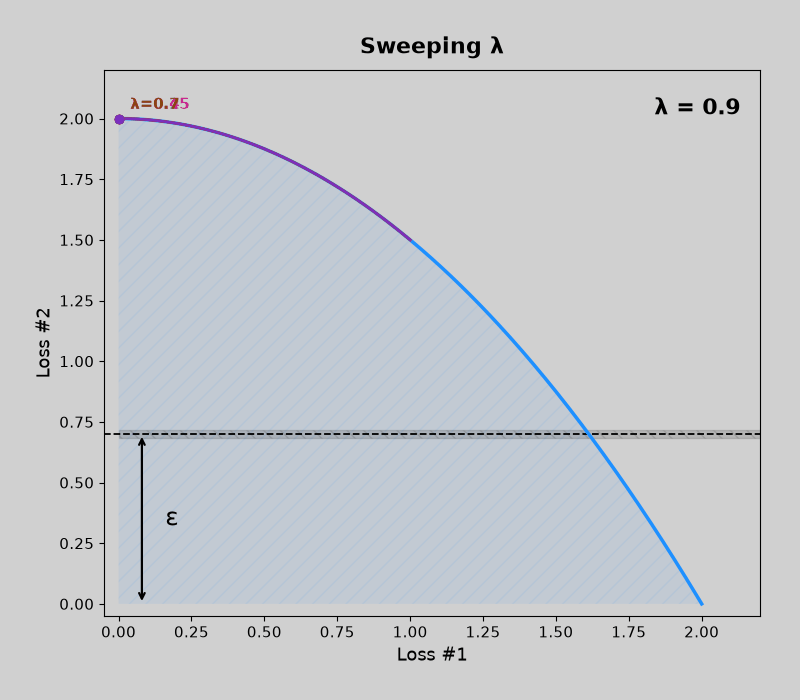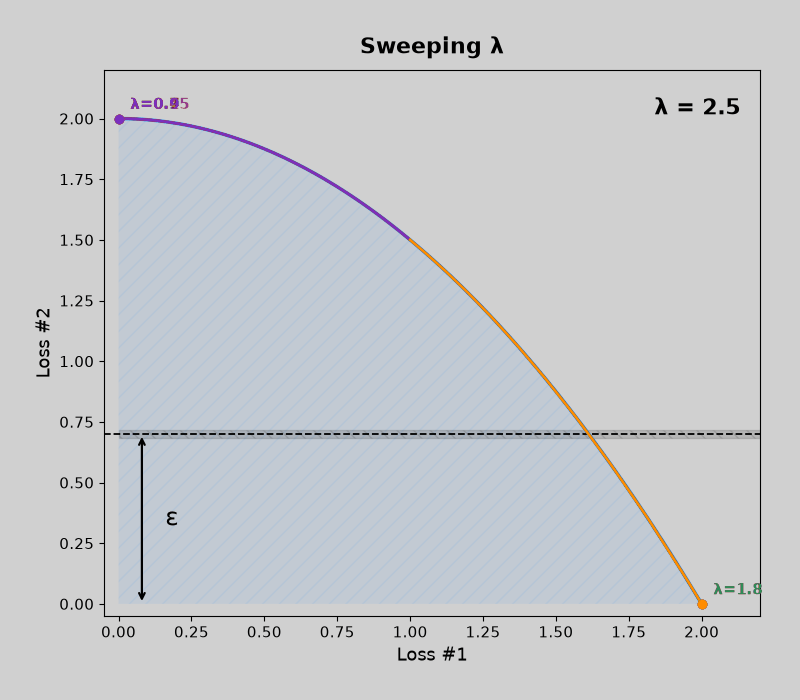
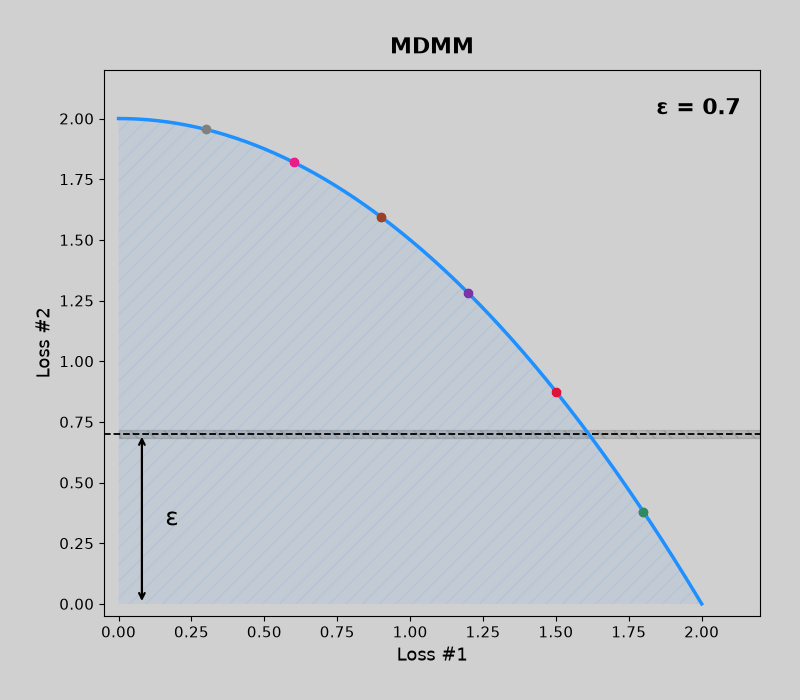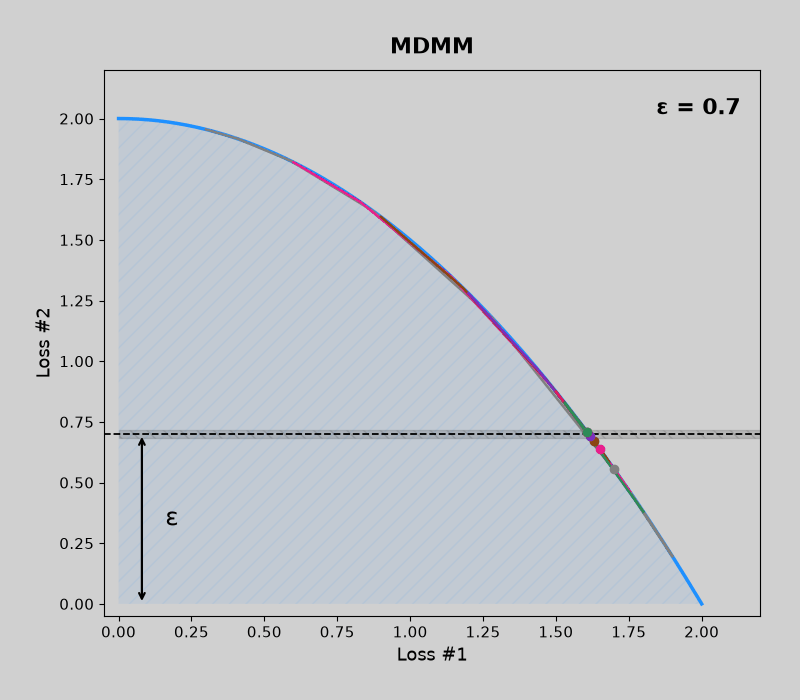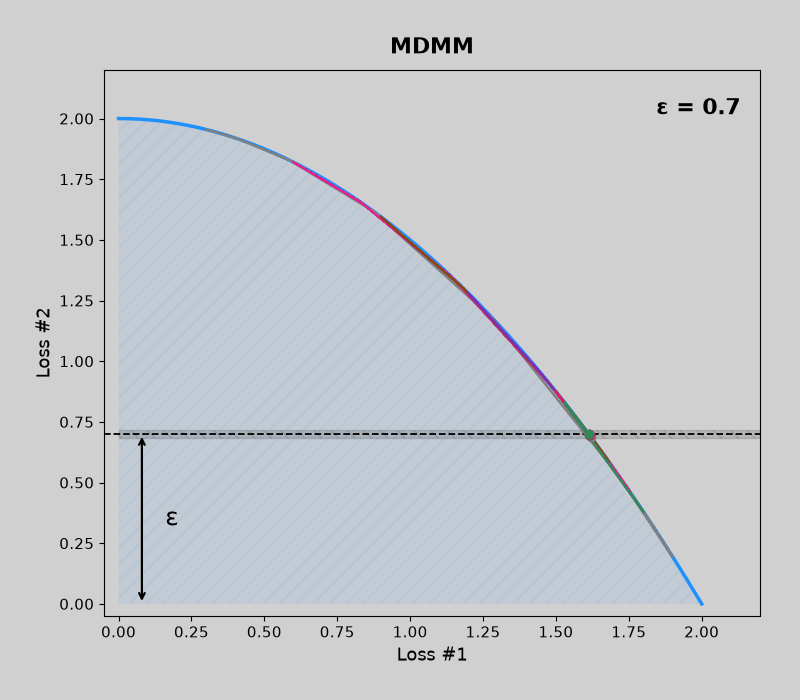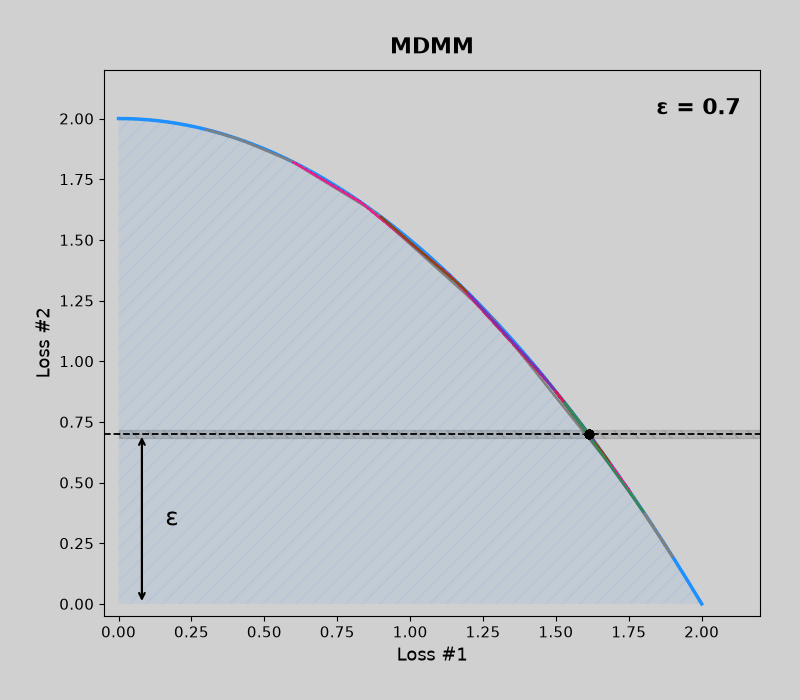
Code
There is a library for MDMM in PyTorch. I provide a functional implementation as well. There is also a JAX implementation.
from mdmm import FunctionalMDMM, MaxConstraintHard
constraint = MaxConstraintHard(max_val=epsilon, damping=5.0)
mdmm = FunctionalMDMM([constraint])
# Initialize dual variables (lambdas) to zero
params["mdmm"] = mdmm.init_state(batch_size, device)
# Inside the loss function:
mdmm_ret = mdmm(params["mdmm"], [f1_value])
total_loss = f0_loss + mdmm_ret.value
# Dual variables use gradient ascent -- invert their grads after backward:
grads["mdmm"]["lambdas"] = -grads["mdmm"]["lambdas"]